8. フィッティング
この章では、最小二乗法 (least squares) を使ってデータにモデルをフィッティングする際の基本原理を扱います。 フィッティングには CurveFit.jl パッケージを使います。
最小二乗フィッティング
Section titled “最小二乗フィッティング”個のデータ点の組 (ただし ) からなる実験データがあるとします。 は で観測された値です。 モデルがデータをどの程度説明できるかを調べ、モデルの関数がデータに最も「フィット」するまでモデルのパラメータを調整することで、このデータから物理的な知見を得たいと考えます。 たとえば、液体サンプルの吸光度をさまざまな濃度で測定すると、吸光度と濃度の間に線形関係があると期待されます (有名な Beer-Lambert 則)。 測定した吸光度と線形モデルとの差が誤差です。 直線の傾きと切片が、データに最もよく合致する直線を見つけるために変化させるパラメータです。
研究対象の系がどのようなものであれ、データに最もよくフィットするモデルを生み出すパラメータが、測定した物理系について何か有益なことを示してくれることを期待します。 物理的に妥当なモデルを選ぶこと以外に、モデルがデータにどれだけ「フィット」しているかを定量化する必要もあります。 モデル関数は という形を取り、ここで はフィッティングによって求めたいパラメータのベクトルです。 この「ベストフィット」のパラメータベクトルを見つけることが目的です。 モデルがデータにどれだけ合っているかは、観測値 と、与えられた に対するモデル値 との差で測ります。 この差の集合は残差 (residuals) と呼ばれ、次のように定義されます。
最小二乗法では、残差を二乗してすべて足し合わせます。 この二乗残差の和を最小化することで、最適なパラメータ値 が得られます。 二乗残差の和は次の式で与えられます。
この関数はコスト関数または 損失関数 (loss function) とも呼ばれます。誤差関数 (error function) と呼ばれることもあります。
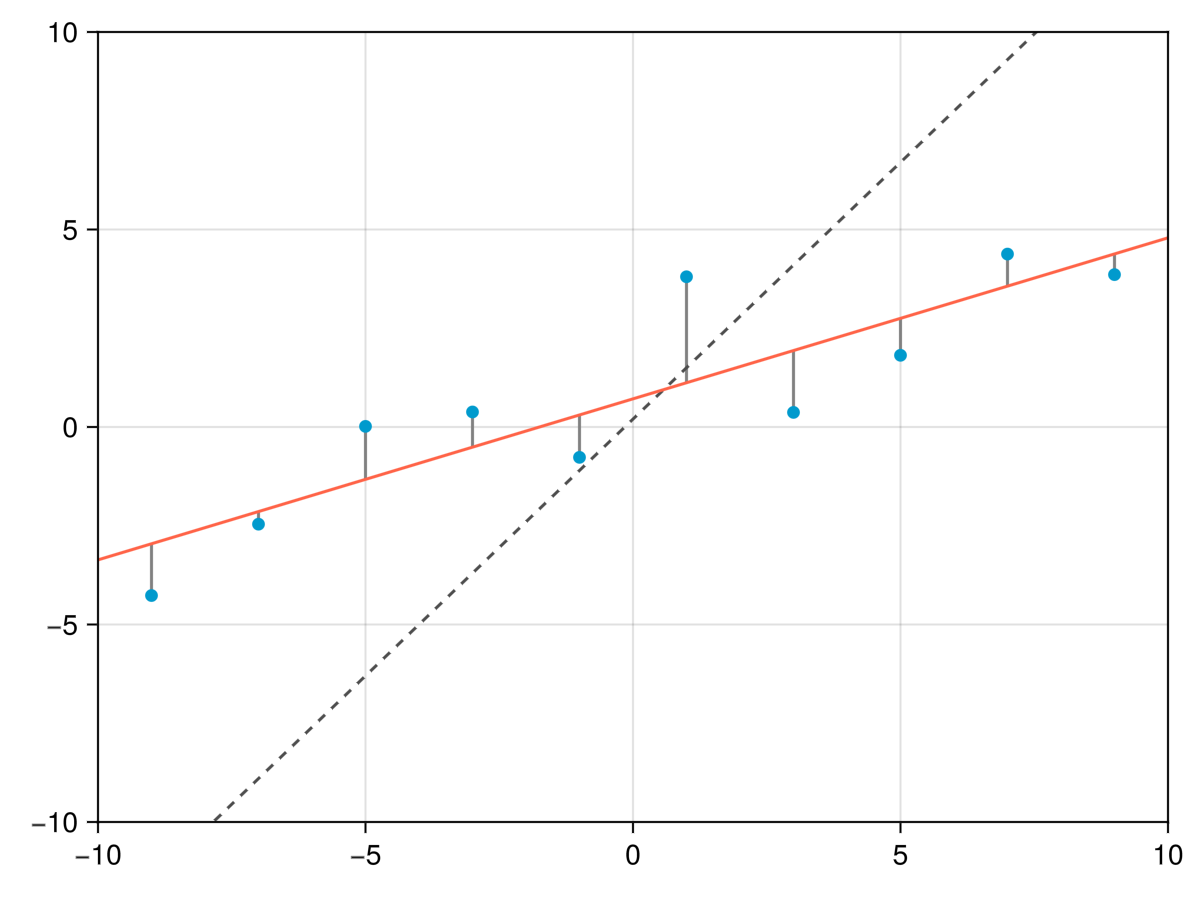
下の例は、ランダムに生成したデータに対する線形フィットと、データ点と当てはめ直線の間の線として描画した残差を示しています。 点線は初期推定パラメータでの直線です。
例: ローレンツ型のピーク
Section titled “例: ローレンツ型のピーク”ノイズの多いサンプルのスペクトルを測定し、500 nm 付近にひとつのピークを観測したとします。分光学でよく現れる線形であるローレンツ関数 (Lorentzian) でこのピークが表せると考える理由があるとしましょう。 ローレンツ型のラインシェイプは次の式で与えられます。
ここで は振幅、 はピークの中心周波数 (波数で表されることが多い)、 は半値全幅 (FWHM) で、 の点で現れます。
CurveFit.jl の NonlinearCurveFitProblem と solve を使って、以下のパラメータでローレンツ関数をフィッティングしてみましょう。モデル関数のシグネチャは f(p, x)、つまりパラメータベクトルが先、独立変数が後です。フィッティング後、ベストフィットパラメータは coef(sol) で、その標準誤差は stderror(sol) で取得します。
A = 1.0Γ = 28x0 = 510データ点の数や加えるノイズの量によりますが、結果は下のようなものになるはずです。 各パラメータの誤差推定値も忘れずに報告してください。
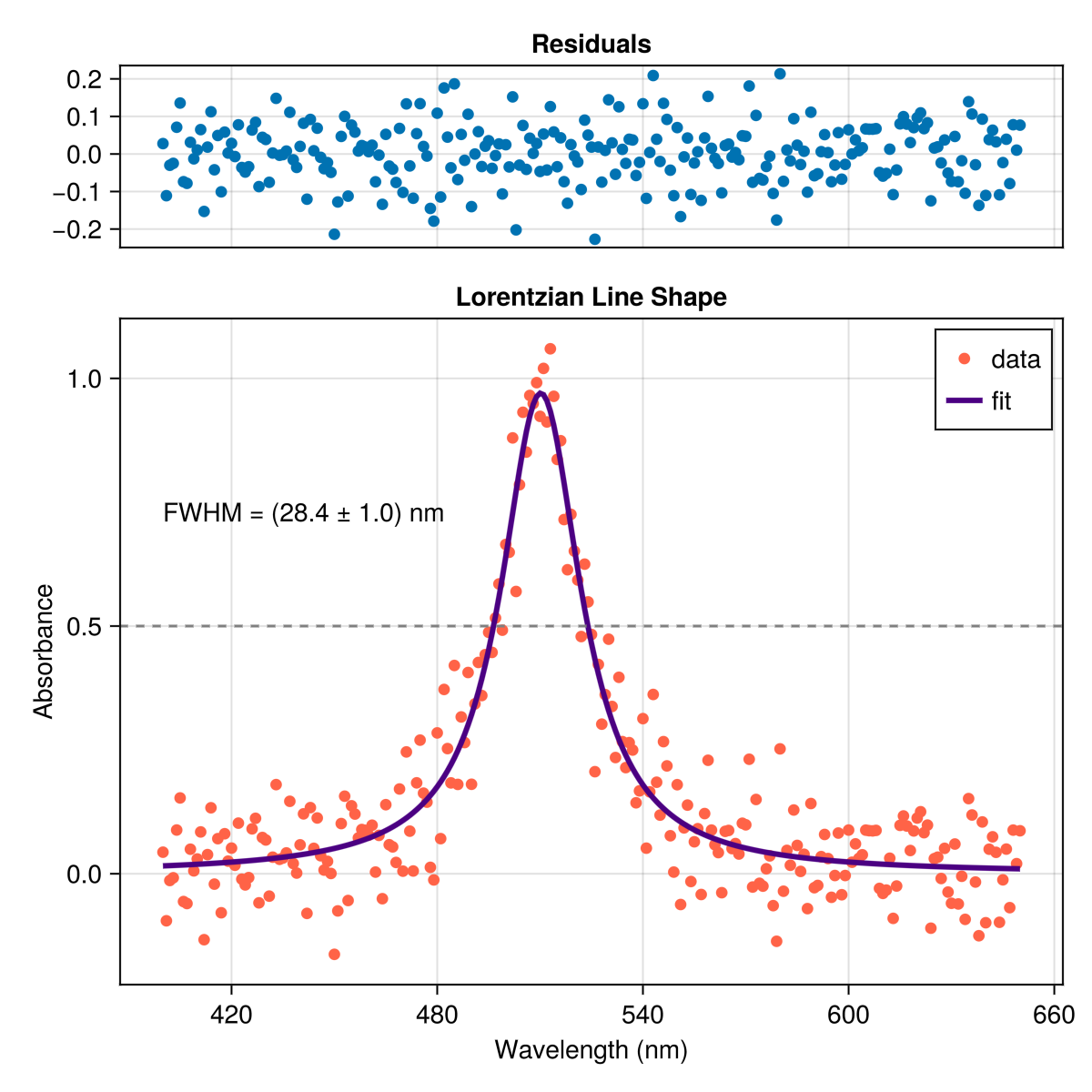
フィット結果の残差をプロットして、結果がデータにどれだけ合っているかを確認するのは有用です。 残差に系統的な構造が見られないことが望ましく、もし見られればモデルがデータをうまく説明できていないことを意味します。
例: ポラリトン分散
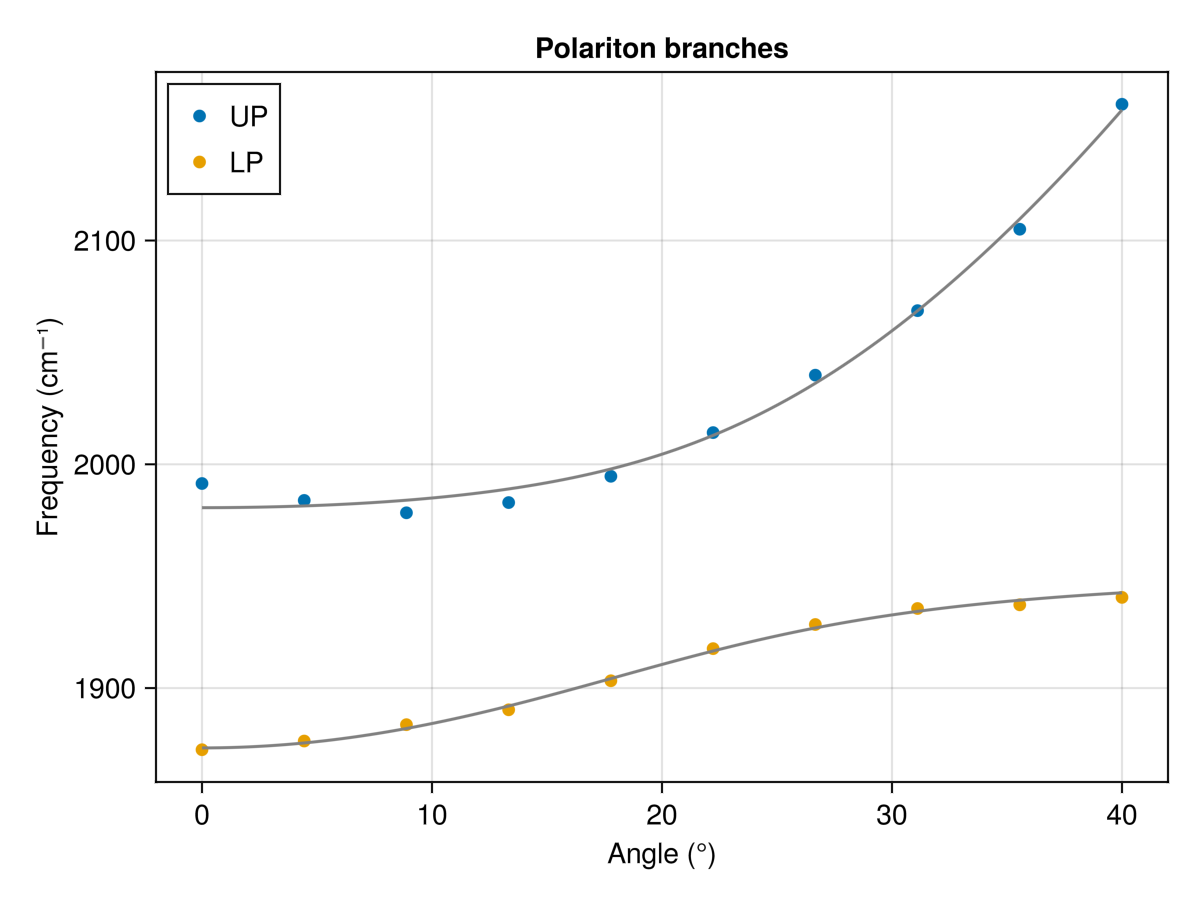
Section titled “例: ポラリトン分散”ポラリトン系の Rabi 分裂を、ビーム入射角の関数として測定するとしましょう。 透過スペクトル中には 2 つのピークが現れ、一方はアッパーポラリトン、もう一方はロワーポラリトンに対応し、それぞれ角度に応じて周波数が変化します。 Rabi 分裂を取り出す方法のひとつは、角度分解スペクトルを測定し、周波数を入射角に対してプロットして、次のハミルトニアンで与えられる単純な結合調和振動子モデルでデータをフィッティングすることです。
このハミルトニアンを対角化すると、アッパー/ロワーポラリトンのエネルギーが得られます。
分子振動遷移は 、Rabi 分裂の大きさは です。キャビティモードの周波数 は次の式で与えられます。
ここで はキャビティ表面の法線に対するビームの角度、 はキャビティ内媒質の屈折率です。
2 つのポラリトンブランチを同時にフィッティングするには、両方を返すモデル関数をひとつ書くだけで済みます。アッパーとロワーのブランチの予測値を vcat で連結し、連結したデータと比較します。
using CurveFit
function cavity_mode_energy(θs, E_0, n) # Your code hereend
function polariton_branch(θs, E_v, E_0, n, Ω, branch) # Your code here — branch = +1 for UP, -1 for LPend
function model(p, θs) E_v, E_0, n, Ω = p LP = polariton_branch(θs, E_v, E_0, n, Ω, -1) UP = polariton_branch(θs, E_v, E_0, n, Ω, +1) return vcat(LP, UP)endそして NonlinearCurveFitProblem を構築し、solve() を呼び出します。
prob = NonlinearCurveFitProblem(model, [E_v, E_0, n, Ω], θs, vcat(LP, UP))sol = solve(prob)ベストフィットパラメータは coef(sol)、その標準誤差は stderror(sol) で取得します。
-
上で述べたノイズ入りのローレンツスペクトルをフィッティングしましょう。ピーク位置、FWHM、振幅と、それぞれの標準誤差を報告してください。
-
cavity_mode_energyとpolariton_branch関数を実装しましょう。これらを使って、 = 1900 cm-1、 = 1950 cm-1、 = 60 cm-1、 = 1.4 のパラメータでガウシアンノイズを加えた 2 つのポラリトンブランチのデータを生成してください。 -
NonlinearCurveFitProblemを構築してsolve()を呼び出し、モデルをデータにフィッティングしましょう。パラメータの初期推定値をいろいろ変えてみて、フィット結果にどう影響するかを観察してみてください。 -
フィッティングパラメータの数を変えてみましょう。 上の例では 4 つのパラメータを変動させましたが、既知の値のものを固定することもできます。 たとえば、分子の振動モードは既知である場合が多いです。 各パラメータの標準誤差と信頼区間を必ず報告してください。 これらの量は何を意味するでしょうか?
- Wikipedia の Least Squares Fitting のページ
- Khan Academy の残差と最小二乗回帰の解説
- Ledvij, M. “Curve Fitting Made Easy.” Industrial Physicist 9, 24-27, Apr./May 2003.